1. Python 자료형을 활용
import Pandas as pd # pandas 라이브러리 임포트, 별칭 pd
sample_cate = ["짜장면", "짬뽕", "볶음밥"] # 리스트
sample_price = [7000, 7500, 7500] # 리스트
1) 시리즈를 만들기
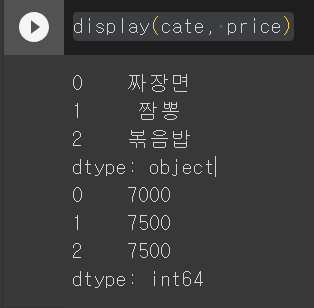
cate = pd.Series(sample_cate) # cate라는 시리즈
price = pd.Series(sample_price) # price라는 시리즈
display(cate, price)
2) 데이터프레임 만들기
(1) 두 개의 시리즈를 통해 만들기
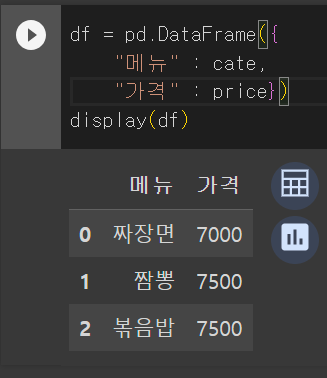
df = pd.DataFrame({
"메뉴" : cate,
"가격" : price})
display(df)
(2) dictionary를 통해 만들기
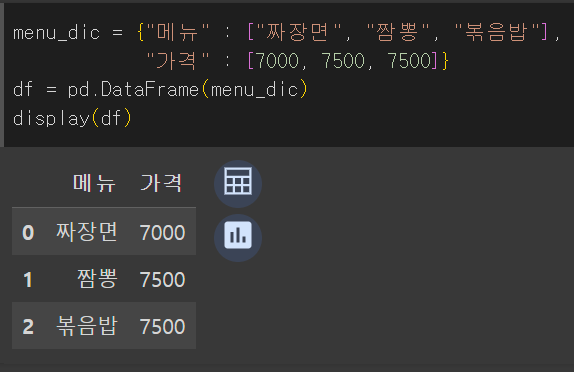
menu_dic = {"메뉴" : ["짜장면", "짬뽕", "볶음밥"],
"가격" : [7000, 7500, 7500]}
df = pd.DataFrame(menu_dic)
display(df)
★ 단, 위의 방법들로 만들때, dictionary의 value에 있는 리스트들의 요소 개수가 맞지 않으면 오류가 일어남
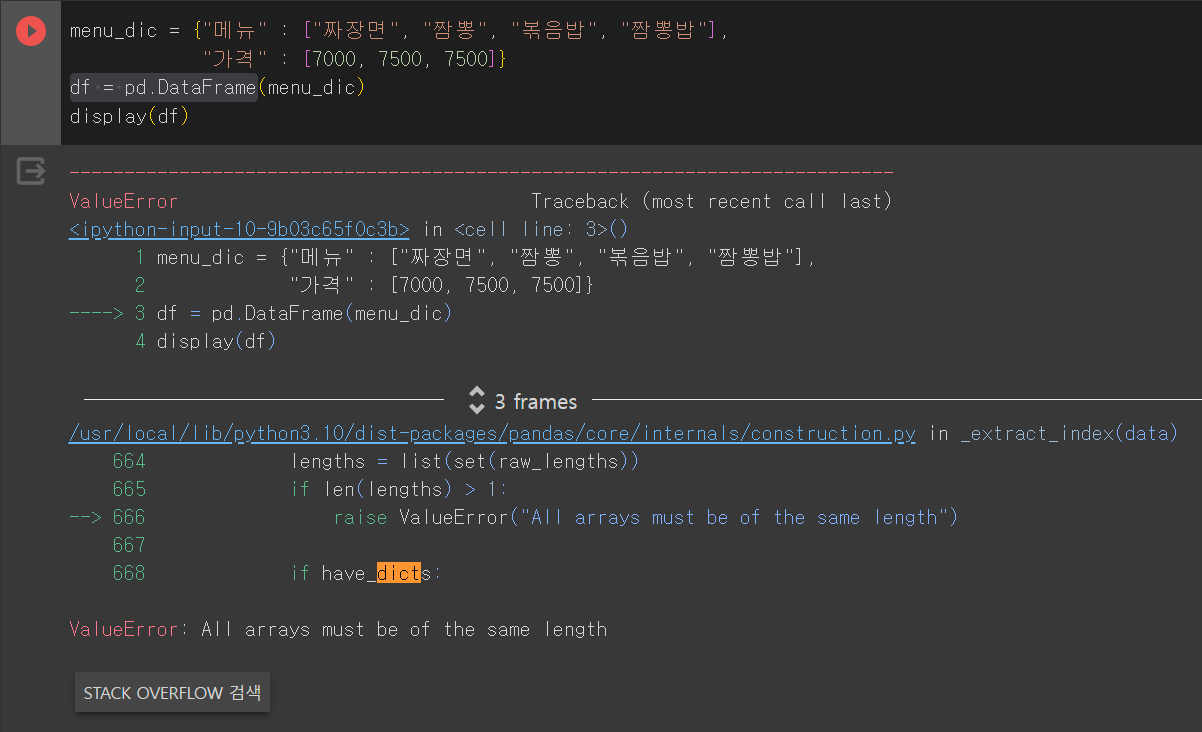
★ ★ 자동으로 안맞는 갯수만큼 Nan값 생성해서 데이터프레임화 하는 방법
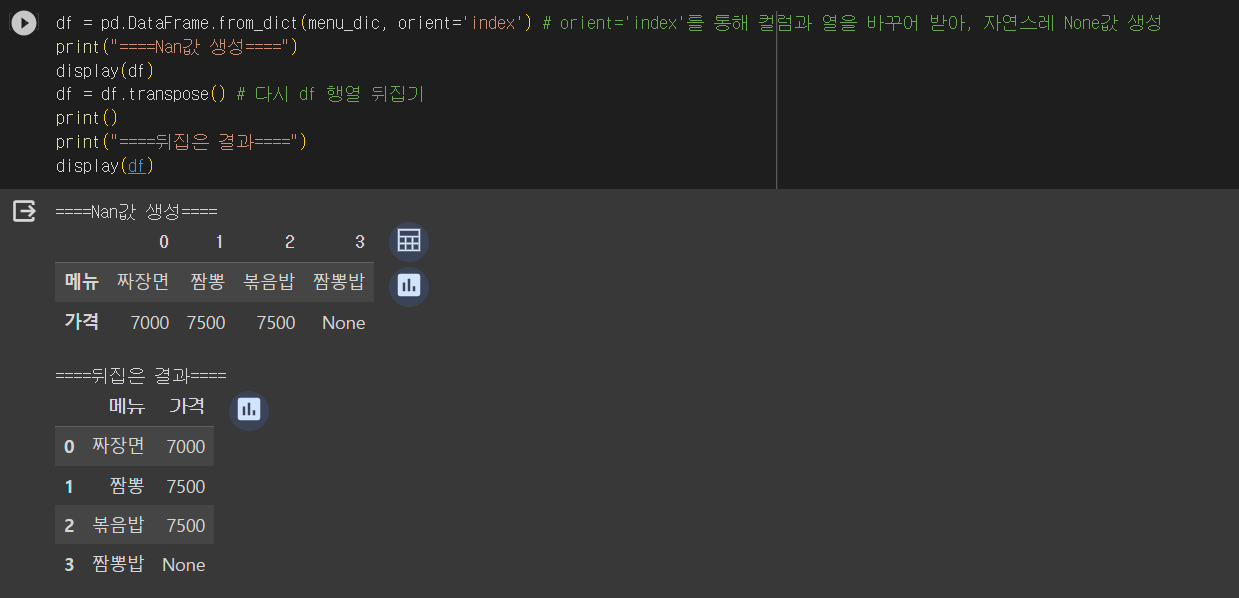
df = pd.DataFrame.from_dict(menu_dic, orient='index') # orient='index'를 통해 컬럼과 열을 바꾸어 받아, 자연스레 None값 생성
df = df.transpose() # 다시 뒤집기
display(df)
2. CSV파일을 활용
df = pd.read_csv("https://raw.githubusercontent.com/NeatyNut/csv/main/sample_csv.csv")
# df = pd.read_csv("파일.csv")
df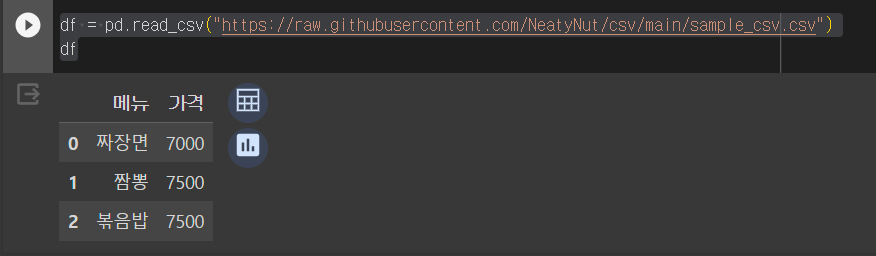
df = pd.read_csv("https://raw.githubusercontent.com/NeatyNut/csv/main/sample_csv.csv", index_col="메뉴")
df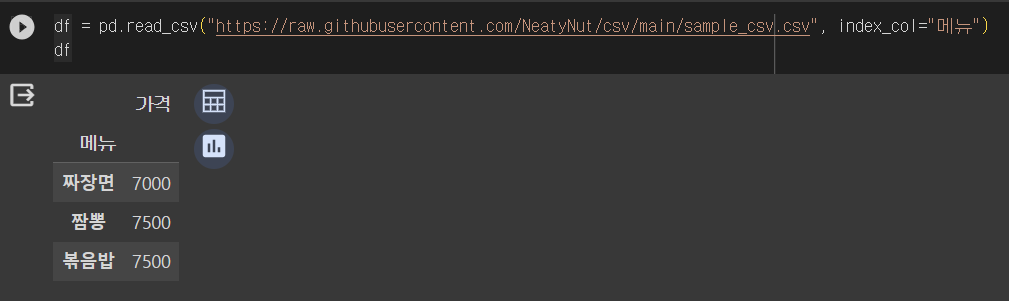
★ 원본csv 인코딩 방식에 따라 한글이 깨질 경우, read_csv("파일.csv", encoding="cp949")로 바꿔주시면 됩니다!
'Python > Pandas' 카테고리의 다른 글
| Pandas의 기초 - 데이터 가공(정렬, 그룹핑) (4) | 2023.11.21 |
|---|---|
| Pandas의 기초 - 데이터 가공(데이터프레임 복사 / 데이터 삭제, 결측치 다루기) (1) | 2023.11.21 |
| Pandas의 기초 - 데이터 선택 (0) | 2023.11.20 |
| Pandas의 기초 - 데이터 확인 (1) | 2023.11.20 |
| Pandas의 기초 - Series와 DataFrame (0) | 2023.11.20 |



