1. 정렬(Index 또는 특정 col의 값 기준으로)
1) 인덱스 기준(sort_index())
data.sort_index(ascending=True) # 오름차순(ascending 생략가능)
data.sort_index(ascending=False) # 내림차순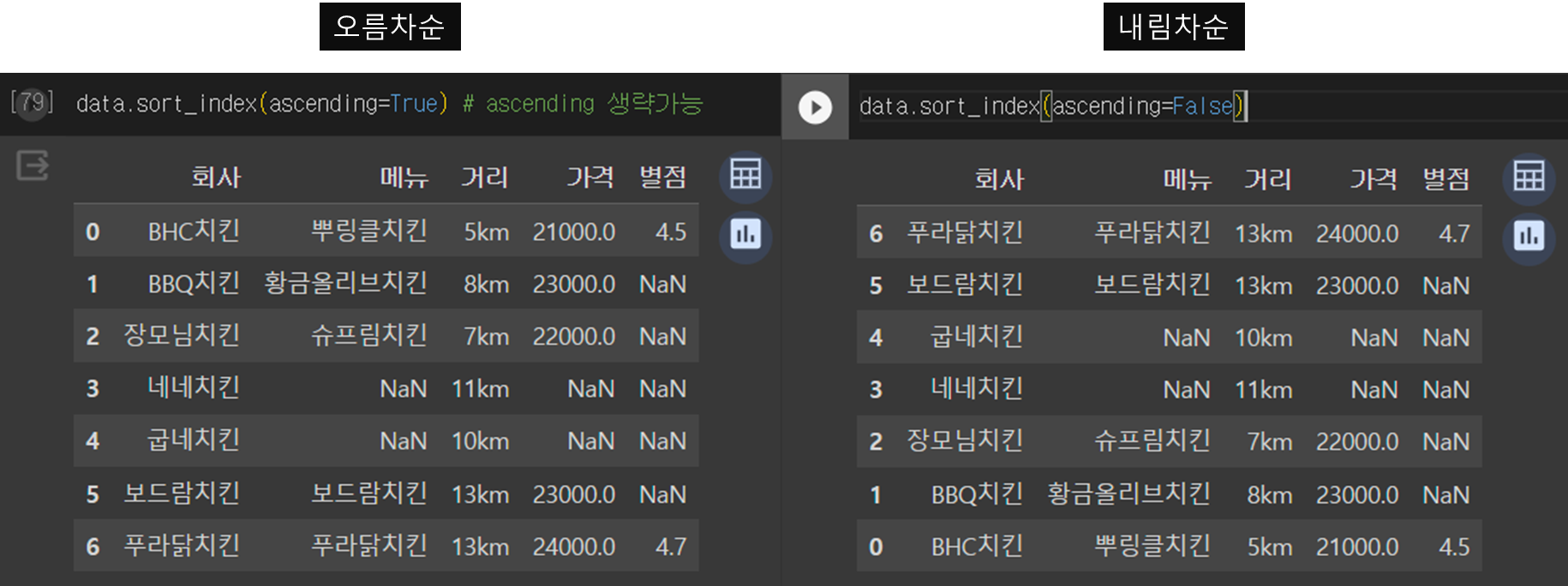
2) 특정 col의 값 기준(sort_values())
# "회사"컬럼만을 기준으로 정렬할때
data.sort_values("회사", ascending=True) # ascending은 생략가능
# "회사", "메뉴"순으로 정렬할때
data.sort_values(by=["가격","회사"], ascending=[True, False])
2. 그룹별 집계(Groupby())
data.groupby("가격").count() #.count()는 sum이나 mean 등 다른 집계방식으로 대체 가능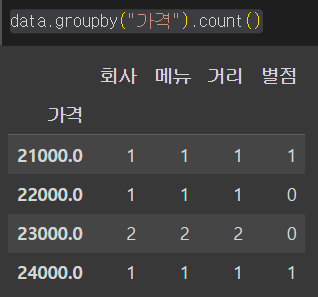
★ 특정 컬럼들만을 집계 가능하다.( [컬럼 1개]는 시리즈, [[컬럼 N개(1개 가능)]]는 데이터프레임
data.groupby("가격")["메뉴"].count() # Series로 반환
data.groupby("가격")[["회사","메뉴"]].count() # Dataframe으로 반환
data.groupby(["가격","거리"])["회사"].count() # Series로 반환
★ ★ 각종 내장함수 모음
df["가격"].mean() #평균
df["가격"].var() #분산
df["가격"].std() #표준편차
df["가격"].quantile(0.25) # 1분위수
df["가격"].median() #중앙값(2분위수)
df["가격"].quantile(0.75) # 3분위수
df["가격"].max() #최대값
df["가격"].min() #최소값
df["가격"].mod() #최빈값
3. 데이터 타입 가공(astype())
data["거리"] = data["거리"].str.replace("km","") # km문자열 제거
data["거리"] = data["거리"].astype(int) # 숫자형으로 변환
data
# 물론 아래와 같이 붙여서 함께 쓰는 것도 가능하다
data["거리"] = data["거리"].str.replace("km","").astype(int)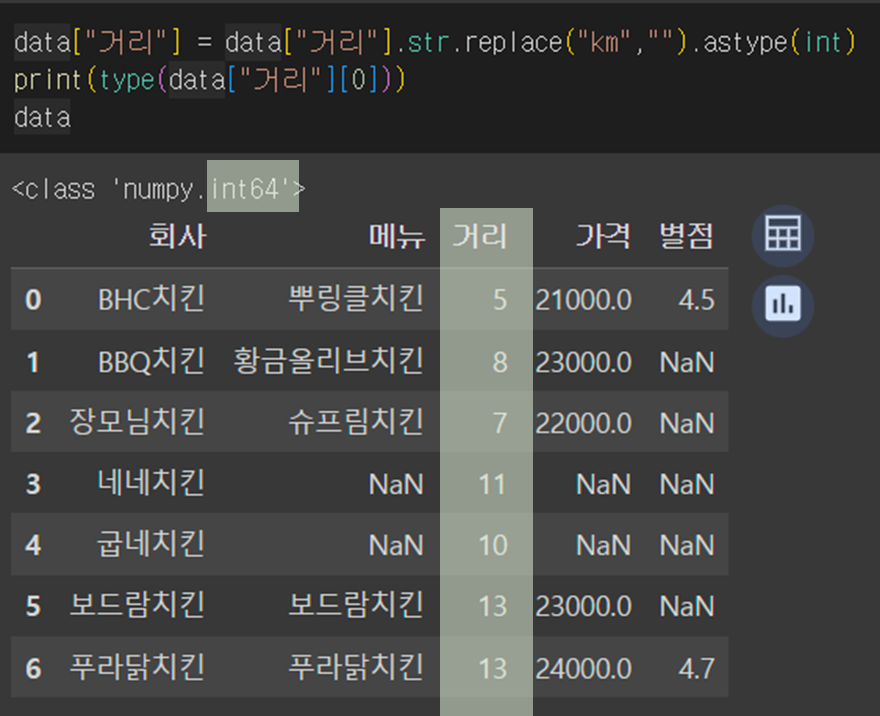
'Python > Pandas' 카테고리의 다른 글
| Pandas의 기초 - 데이터 가공(데이터프레임 복사 / 데이터 삭제, 결측치 다루기) (1) | 2023.11.21 |
|---|---|
| Pandas의 기초 - 데이터 선택 (0) | 2023.11.20 |
| Pandas의 기초 - 데이터 확인 (1) | 2023.11.20 |
| Pandas의 기초 - Series와 DataFrame 만들기 (1) | 2023.11.20 |
| Pandas의 기초 - Series와 DataFrame (0) | 2023.11.20 |



